K-Means Cluster
1. Define KMC.
KMC is an unsupervised learning algorithm that attempts to divide the data into distinct groups such that observations within each group are similar or share some certain similarities.
2. Explain KMC’s main assumptions.
Similar to KNN, KMC assumes that similar things exist in close proximity.
3. Explain the disadvantage of KMC of assuming that the clusters to have equal variance and equal sizes.
KMC assumes that clusters have similar sizes and equal variances. If the clusters are different sizes, the centroids will be biased towards the larger clusters. This is because the larger clusters will have more data points, which will pull the centroids towards them. If the clusters do not have equal variances, they may not be well-separated. This is because the clusters with higher variances will be more spread out, making it more difficult to distinguish them from other clusters.
4. Explain the disadvantage of KMC being sensitive to initialisation.
KMC’s performance is sensitive to the initial placement of cluster centroids. Different initialisations can lead to different clustering results, including local optima.
5. State and explain the advantages KMC.
- Ease of Implementation: KMC is straightforward to understand and implement, making it an accessible choice for clustering tasks.
- Speed and Scalability: KMC is computationally efficient and can handle large datasets and high-dimensional data relatively well compared to some other clustering algorithms.
6. List the disadvantages of KMC.
- Sensitivity to Initialisation.
- Assumption of Equal Variance.
- Outlier Sensitivity.
7. Explain the hyperparameter (k).
It determines the number of clusters the algorithm should partition the data into.
8. State the negative implications of choosing too many k (clusters).
- Overfitting Risk: Selecting too many clusters can lead to overfitting, where the model creates small and overly specific clusters that capture noise in the data.
- Loss of Interpretability: When K is too large, it becomes challenging to interpret and make sense of the resulting clusters.
- Increased Computational Complexity: More clusters mean more centroids to calculate and more data points to assign to clusters, resulting in increased computational complexity.
9. State the negative implication of choosing too few k.
Underfitting Risk: Selecting too few clusters can lead to underfitting, where the model fails to capture distinct patterns in the data. The clusters may become too broad and fail to distinguish meaningful subgroups.
10. State and explain the steps to perform KMC.
- Select K Centroids: The algorithm will randomly initialise K centroids, which are points in the feature space.
- Compute Distance: Compute the Euclidean distance of each datapoint with each centroid (all of it).
- Assign Points to Clusters: Assign all the points closest to the nearest clusters based on the computed distance.
- Recalculate Centroids: Recalculate the centroids by calculating the means of all the data points assigned to each cluster.
- Repeat Step 2-4: Steps 2 to 5 are iteratively repeated until convergence, where the centroids no longer change significantly or a predefined number of iterations is reached.
11. Describe the goal of KMC in terms of variance.
KMC aims to maximise variance between clusters to make the clusters as distinct from each other as possible and minimise variance within groups to ensure that the data points within the clusters are similar to each other.
12. Define Centroids in the context of KMC.
A centroid is the location representing the centre of the cluster.
13. Euclidean distance is the most common choice to calculate the centroid of each cluster. Explain Euclidean distance and provide the formula for Euclidean distance to calculate two dimension space.
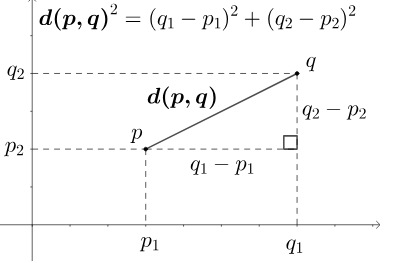
Image Source: https://en.wikipedia.org/wiki/Euclidean_distance#/media/File:Euclidean_distance_2d.svg
{kind=link}
The Euclidean distance is a measure of the straight-line in distance between two points in Euclidean space (a space where distances are measured in a way that’s consistent with the Pythagorean theorem).
The formula for Euclidean distance between two points P and Q in two dimension space:
$d(p,q) = \sqrt{\sum_{i=1}^{n}(q_1 - p_1)^2 + (q_2 - p_2)^2}$
14. List the methods to choose the optimal K.
- Elbow Method: Plot sum of squared distances of the data points to their assigned cluster centroids as a function of K. Select the K where the rate of decrease changes drastically.
- Silhouette Score: Calculate the silhouette score for different K values and choose the K that yields the highest silhouette score. A higher silhouette score indicates better-defined and well-separated clusters.
15. List some common use-cases for KMC.
- Customer segmentation: Businesses can use KMC to segment their customer base into distinct groups based on purchasing behavior, demographics, or preferences.
- Anomaly Detection: KMC can help identify anomalies or outliers in data by clustering the majority of data points into groups and flagging data points that do not belong to any cluster as potential anomalies.
- Document Clustering: In natural language processing (NLP), KMC can be applied to cluster similar documents, articles, or news stories for content organisation, recommendation systems, and topic modeling.
- Fraud Detection: Financial institutions can employ KMC to identify patterns of fraudulent transactions by clustering normal and anomalous transaction behaviours.