DBSCAN
1. What does DBSCAN stands for?
2. How does DBSCAN work intuitively?
3. Explain DBSCAN hyperparameters eps and minPoints.
eps: specifies how close points should be to each other to be considered a part of a cluster. If distance between two points is lower or equal to this value (eps), these points are considered to be neighbours.minPoints:The minimum number of points to form a dense region.
4. Explain Core Point, Border Point and Noise Point.
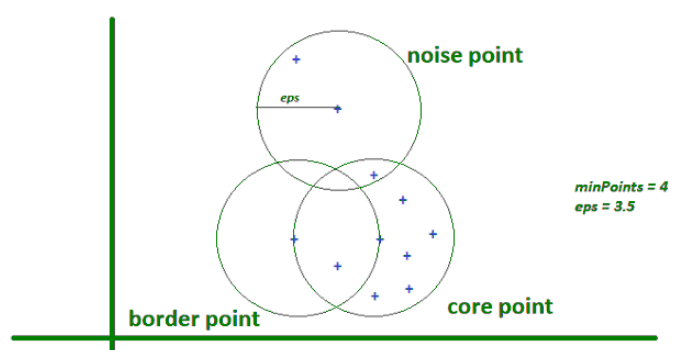
Image Source: https://shritam.medium.com/how-dbscan-algorithm-works-2b5bef80fb3
- Core Point:
- A core point is a point that has
≥ minPointswithin theepsradius around it. - It is always in a dense region
- A core point is a point that has
- Border Point:
- A border point is a point that has
< minPointsinepsradius and it is in the neighbourhood of a core point (at least one core point in the neighbourhood)
- A border point is a point that has
- Noise Point:
- Any point that is not a core point or a border point.
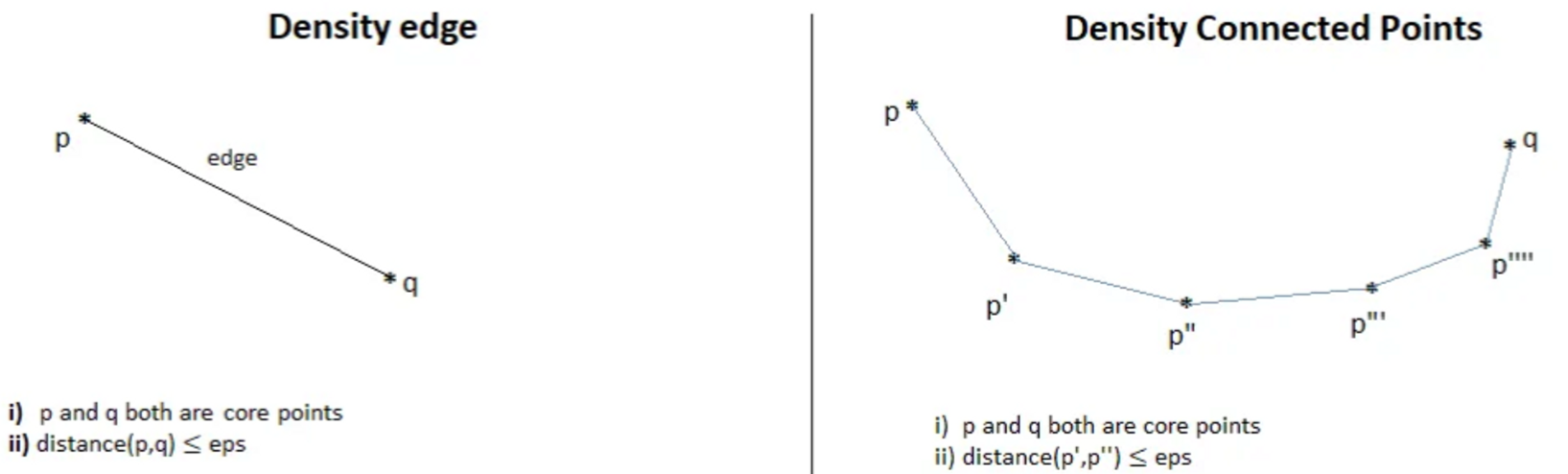
5. Explain Density Edge and Density Connected Points.
6. Is it harder to build a cluster if both minPoint and eps decrease?
eps makes it harder to form cluster.
7. Is it harder to build a cluster if both minPoint and eps increase?
eps makes it easier to form cluster.
8. Is it harder to build a cluster if minPoint increases but eps remains the same?
9. Is it harder to build a cluster if eps increases but minPoint remains the same?
10. Provide a general guideline to select the appropriate minPoint value.
- The
minPointshould be more than or equals to the dimension. - For larger datasets, we should increase the
minPoint.
11. Explain the implications if eps is set too high.
Setting a high epsvalue means that the algorithm considers data points as neighbours even when they are relatively far apart, making it easier to group data points into clusters.
When eps is set too high, it will likely to lead to underfitting because DBSCAN may merge distinct clusters into a single large cluster or include outliers. This leads to a loss of discriminative power and the clusters may not accurately represent the underlying patterns in the data.
12. Explain how knee method is used to determine the appropriate eps.
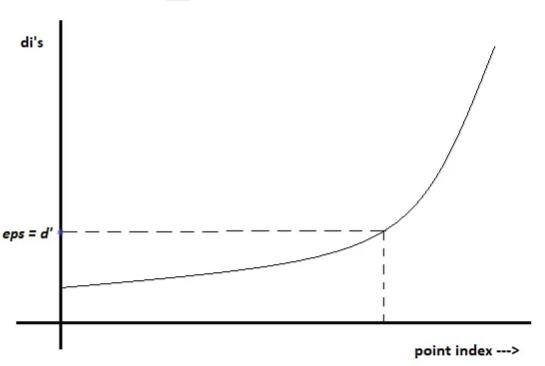
Where y = eps, x = points (sample) sorted by distance
Image Source: https://shritam.medium.com/how-dbscan-algorithm-works-2b5bef80fb3
eps is the maximum distance between two points to be considered as neighbours.
- How it works:
- Select the appropriate
minPoint=k. - Compute the average distance between every point to its k nearest neighbours.
- Plot the k-distance in ascending order. Note that every point will have different distances.
- Select the k-distance where the rate of increase changes drastically. The intuition is that the k-distance of core points and border points falls within a specific range, whereas noise points may exhibit significantly greater k-distances.
- Select the appropriate
13. State and explain the steps to perform DBSCAN.
- Initialisation:
- Select the appropriate values for
epsandminPoints
- Select the appropriate values for
- Core Point Identification:
- For each data point, calculate the distance
di. - If
di ≤ eps, the data point categorised as the neighbour of the point x. - If a data point has more neighbours than
minPoints, it will be marked as core point.
- For each data point, calculate the distance
- Cluster Formation:
- Select a random core point to create a cluster.
- Connect the core points together that are within the datapoint’s
epsto form the first cluster.
- Border Point Assignments:
- Assign each border points to the cluster of the closest core point. Note that border points cannot extend the cluster further, they can only join a cluster.
- Noise Point Identification:
- Any unvisited data points that are not core nor border points will be treated as outliers relative to the cluster.
- Repeat for unvisited Core Points:
- Repeat the cluster formation process for all unvisited core points, iteratively creating additional clusters as long as there are unvisited core points to start from.
14. Explain why DBSCAN is able to noise effectively.
15. List the advantages of DBSCAN.
- Handles Noise Data effectively.
- Robust to different shaped clusters.
- No need to specify the number of clusters (k).
- Adaptive to data density.
- Natural Handling of Outliers.
16. List and explain the disadvantages of DBSCAN.
- Difficulty with varying density: When clusters in the data have significantly different densities, it can be challenging to find a single set of parameter values that work well for all clusters.
- Computationally expensive: In datasets with high dimensionality or when using certain distance metrics, DBSCAN’s memory and computational requirements can become substantial.