Gradient Descent & Loss Function
Loss Functions
1. Define loss functions (cost functions) and the main purpose.
Loss function quantify the errors or discrepancy between the predicted values of a model and the actual target values.
The main purpose is to guide the learning process by providing a measure of how well or poorly a model is performing.
2. List the two common regression loss functions.
- Mean Squared Error (MSE) - Sum of the mean squared errors.
- Mean Absolute Error (MAE) - Sum of the mean absolute errors.
3. State the common loss function for binary classification problem.
4. State the common loss function for multi-class classification problem.
5. What is the training objective for the loss function in supervised learning?
6. Does loss function have to be evaluation metric in assessing the model performance? Provide an example.
7. Why it is important to select the appropriate loss function?
8. Provide the sum of squared errors formula for a linear equation $\hat{y} =a + \beta x_i$.
Gradient Descent
1. Explain gradient descent and the main purpose.
2. Why gradient descent algorithm is called gradient descent intuitively?
3. State how gradient descent finds the optimal values efficiently.
4. State the difference between Ordinary Least Squares Technique (OLS) and gradient descent (GD) and explain the advantage of GD over OLS.
5. List the 4 key steps of gradient descent. (Hint: I-D-U-R)
- Initialise: Randomly initialise the parameter value.
- Derive: Find the slope of the loss function by computing the derivative of the loss function at that point (parameter value)
- Update: Update the parameter value with the step size.
- Repeat: Repeat step 2 and 3 until the GD reach local minimum or the stopping criterion.
6. Given $\hat{y} = \beta_0 + \beta_1x$, explain how to optimise $\beta_0$ using the gradient descent approach.
-
Initialise the intercept value $\beta_0$ = 0.
-
Calculate the partial derivative of the loss function at that point (parameter value) to find the slope with respect to the parameter.
$$ \frac{d(L)}{d(\beta_0)} \ $$
Note: Partial derivative is the derivative of a function of several variables with respect to change in just one of its variables. All other variables will be treated as constants. For example, to find the partial derivative with respect to $\beta_0$, we treat $\beta_1$ as a constant, resulting $\beta_1 = 0$.
-
Update the new intercept by moving a proportional step in the opposite direction of the derivative.
$$ \beta_0^{(k+1)} = \beta_0^{(k)} -n\frac{dL}{d\beta_0}(\beta_0^{(k)}) \ \text{New } \beta_0 = \text{Old } \beta_0 - \text{Step Size} $$
Where, $n$ is the learning rate.
Note:
- The step-size is proportional to the derivative value with a chosen Learning Rate ($n$)
- The updated intercept value will be used for the next iteration.
-
Repeat step 2 and 3 again until the GD reach the local minimum of the loss function.
7. Explain why we move in the opposite direction of the derivative result, that is, we increase the parameter value when the derivative is negative.
8. Explain the negative implications of small learning rate.
- Slow Convergence: Small learning rates can result in slow convergence, meaning it takes a long time for the optimization algorithm to reach the minimum of the loss function
- Getting Stuck in Local Minima: With a very small learning rate, the optimization algorithm may become overly cautious and get stuck in local minima or saddle points.
9. Explain the negative implications of large learning rate.
- Overshooting the Minimum: Large learning rates can cause the algorithm to take excessively large steps in the parameter space during each iteration.
- Slow Convergence: A large learning rate can actually lead to slower convergence if the algorithm consistently overshoots the minimum and oscillates around it.
10. When the slope (gradient) of a function is equal or close to 0, it indicates a potential minimum of that point. Explain the underlying concept.
11. State the general minimum step size and number of steps to take before stopping the gradient descent optimisation.
- Minimum Step Size: 0.001 or smaller
- Minimum Number of Steps: 1000
12. Given $\hat{y} = \beta_0 + \beta_1x$, briefly describe how to use the gradient descent to co-optimise $\beta_0 \text{ and } \beta_2$.
Simply, re-iterate the same procedure for both parameters simultaneously:
- Initialise the two variables with random values.
- Compute the gradients for the loss function with respect to both variables using the partial derivatives.
- Update the variables simultaneously.
13. Given $\hat{y} = \beta_0 + \beta_1x$, explain the process of deriving the SSE for $\beta_0$ (Which will be similar for $\beta_{1}$)
SSE Formula
$$ SSE = \sum(y_i -\hat{y_i})^2 \ SSE = \sum(y_i - (b_0 + \beta x_i))^2\ $$
Deriving SSE to get the loss function’s gradient
-
Applying the sum rule for derivatives, the derivation of the SSE is simply the sum of the derivatives of the individual error.
$$\frac{dL}{da} = \frac{dL}{d\beta_a}(y_1 - (\beta_0 + \beta x_1))^2 + \frac{dL} {d\beta_0}(y_2 - (\beta_0 + \beta x_2))^2 $$ $$+ .. + \frac{dL}{d\beta_0}(y_n - (\beta_0 + \beta x_n))^2 $$
-
Apply the chain rule to derive the individual errors.
$$ \frac{dL}{d\beta_0}(y_1 - (\beta_0 + \beta x_1))^2 $$ $$ \text{Outer } = 2((y_1 - (\beta_0 + \beta x_1)) $$ $$ \text{Inner } = (y_1 - \beta_0 - \beta x_1) = -1 $$ $$ \text{Outer x Inner} = -2(y_1-(\beta_0+\beta x_1)) $$ Note: For the inner function derivation, because we are using partial differentials, all the variables except for $b_0$ will be treated as a constant.
-
Substitute the values into the derived expression for each sample and then aggregate the results to find the gradient.
14. Explain batch gradient descent (BGD).
15. Explain stochastic gradient descent (SGD).
16. Explain mini-batch gradient descent (MBGD).
17. Illustrate the graphs for batch, stochastic and mini-batch gradient descent cost function as the number of iteration increases.
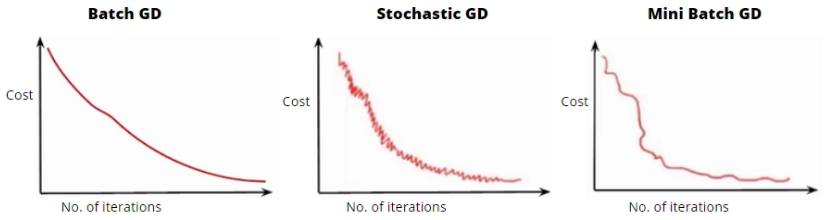
Image Source: https://www.geeksforgeeks.org/ml-mini-batch-gradient-descent-with-python/
- BGD - The average of gradients of all the dataset, the loss function is relatively smooth.
- SGD - The loss function fluctuates from epoch to epoch due to the only using one sample per epoch, making it more volatile.
- MBGD - The balance between speed of convergence and noise associated with gradient update.